基于 Redis + 资源库模式实现 Laravel 应用缓存功能
今天学院君来给大家演示如何在 Laravel 项目中基于 Redis 实现应用缓存功能,这想必也是很多人日常使用 Redis 最多的业务场景,这里的缓存指的是将数据库查询结果存储到 Redis,其目的是将数据加载从磁盘 IO 转化为直接从内存获取,从而提升应用性能。
Web 应用的性能瓶颈通常都是数据库查询,因为磁盘 IO 的效率太低了。
在 Redis 系列开篇中已经介绍过,我们可以通过字符串数据结构来实现应用缓存,如果缓存的是对象实例或者集合而非文本字符串,可以通过序列化方式将其转化为文本格式,读取的时候再通过反序列化方式将其还原。
引入资源库模式
开始之前,我们先将上篇教程对文章模型类 Post 的数据库查询重构为基于资源库模式实现,这样一来,方便我们在资源库这一层引入缓存,从而提升代码复用性,更好地遵循 SOLID 设计原则。
在 app 目录下新建 Repos 子目录存放资源库类,然后在该目录下新建一个与 Post 模型类对应的 PostRepo 资源库类:
<?php
namespace App\Repos;
use App\Models\Post;
class PostRepo
{
protected Post $post;
public function __construct(Post $post)
{
$this->post = $post;
}
}
在 PostRepo 的构造函数中,我们引入了 Post 模型实例作为底层数据源,接下来,就可以编写一个基于主键 ID 获取单篇文章数据的 getById 方法,以及基于多个文章 ID 获取多篇文章数据的 getByManyId 方法了:
public function getById(int $id, array $columns = ['*'])
{
return $this->post->select($columns)->find($id);
}
public function getByManyId(array $ids, array $columns = ['*'], callable $callback = null)
{
$query = $this->post->select($columns)->whereIn('id', $ids);
if ($query) {
$query = $callback($query);
}
return $query->get();
}
这里我们让第二个方法支持传入一个回调函数参数,用于设置额外的查询条件,比如自定义的排序逻辑。
然后我们将更新文章浏览数的逻辑也搬过来:
public function addViews(Post $post)
{
$post->increment('views');
if ($post->save()) {
// 将当前文章浏览数 +1,存储到对应 Sorted Set 的 score 字段
Redis::zincrby('popular_posts', 1, $post->id);
}
return $post->views;
}
在 PostController 控制器中通过 PostRepo 重构对文章模型实例的操作:
<?php
namespace App\Http\Controllers;
use App\Repos\PostRepo;
use Illuminate\Support\Facades\Redis;
class PostController extends Controller
{
protected PostRepo $postRepo;
public function __construct(PostRepo $postRepo)
{
$this->postRepo = $postRepo;
}
// 浏览文章
public function show($id)
{
$post = $this->postRepo->getById($id);
$views = $this->postRepo->addViews($post);
return "Show Post #{$post->id}, Views: {$views}";
}
// 获取热门文章排行榜
public function popular()
{
// 获取浏览器最多的前十篇文章
$postIds = Redis::zrevrange('popular_posts', 0, 9);
if (!$postIds) {
return null;
}
$idsStr = implode(',', $postIds);
$posts = $this->postRepo->getByManyId($postIds, ['*'], function ($query) use ($idsStr) {
return $query->orderByRaw('field(`id`, ' . $idsStr . ')');
});
dump($posts->toArray());
}
}
为了让重构更彻底,我们干脆把获取热门文章排行榜的代码也迁移到 PostRepo 中:
// 热门文章排行榜
public function trending($num = 10)
{
$postIds = Redis::zrevrange('popular_posts', 0, $num - 1);
if (!$postIds) {
return null;
}
$idsStr = implode(',', $postIds);
return $this->getByManyId($postIds, ['*'], function ($query) use ($idsStr) {
return $query->orderByRaw('field(`id`, ' . $idsStr . ')');
});
}
这样一来,PostController 中的 popular 方法实现代码就非常干净简单了:
// 获取热门文章排行榜
public function popular()
{
$posts = $this->postRepo->trending(10);
if ($posts) {
dump($posts->toArray());
}
}
最后,我们将获取文章详情页的路由参数做一下调整,因为现在我们不需要路由模型绑定功能了:
Route::get('/posts/{id}', [PostController::class, 'show'])->where('id', '[0-9]+');
在浏览器中测试这两个路由:

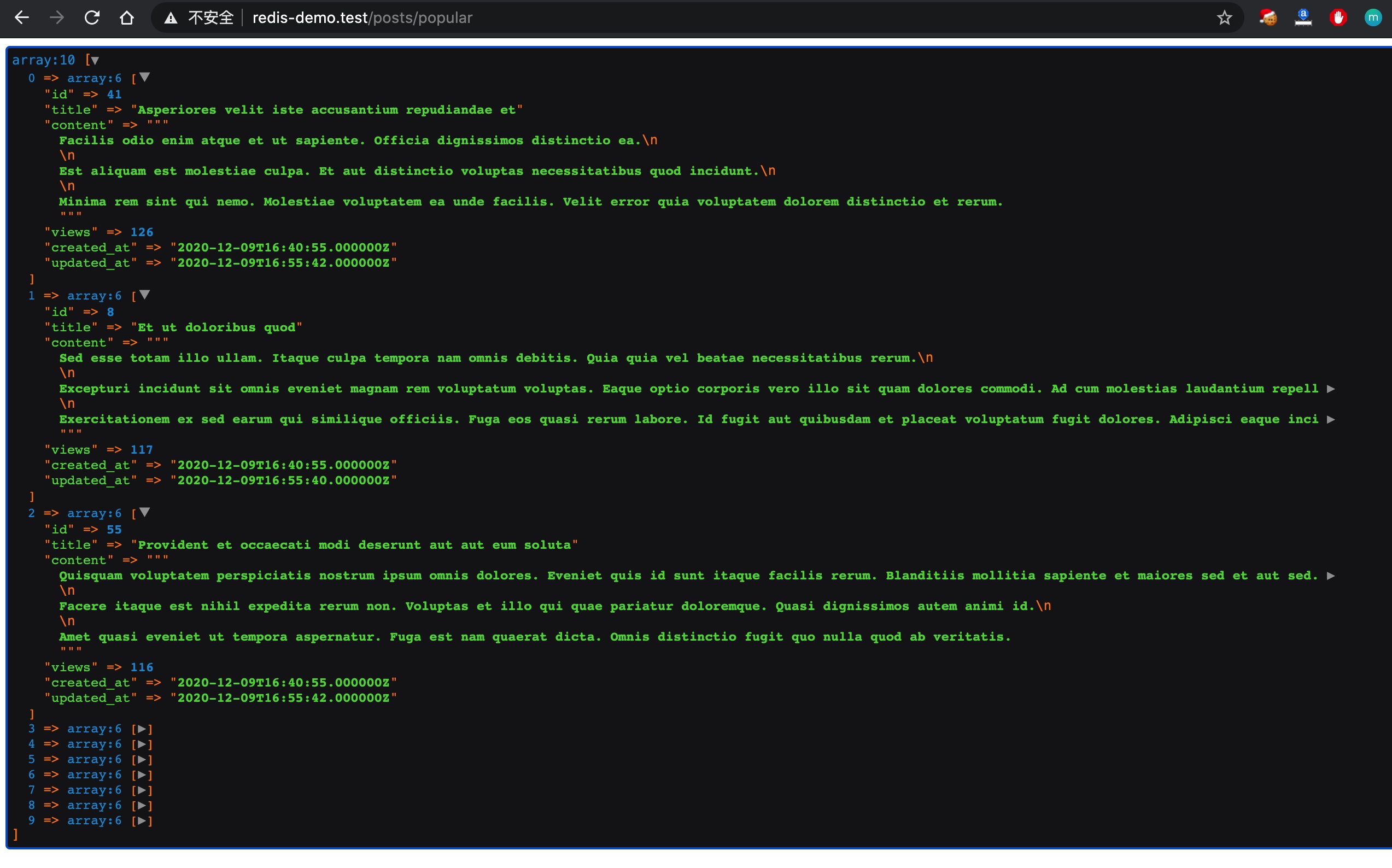
都可以正常返回数据,说明代码重构成功。
通过 Redis 实现缓存功能
接下来,我们通过 Redis 为上面两个路由实现数据缓存功能。Laravel 提供了封装 Redis 存储器的独立缓存组件,不过这里为了方便大家了解底层实现原理,我们先使用原生的 Redis 实现对文章详情数据和排行榜数据的缓存。
正如前面所说,现在我们可以在资源库 PostRepo 这一层对数据库查询结果进行缓存,而不需要调整任何控制器代码。
开始编写缓存代码前,我们先梳理下读取缓存的一般流程:
- 拼接出字符串格式的缓存键;
- 基于
EXISTS指令判断对应缓存项在 Redis 中是否存在; - 若缓存项存在,则通过 Redis 的
GET指令获取该缓存项直接返回(如果缓存项是对象,则通过unserialize方法对其做反序列化操作再返回); - 若缓存项不存在,则先通过数据库查询获取结果,然后基于 Redis 的
SETEX指令将其存储到 Redis(如果待缓存项是对象,则通过serialize方法将其序列化为文本字符串,这里使用SETEX指令的原因是需要设置缓存过期时间),再返回数据库查询结果。
按照上面的思路,重构 PostRepo 的 getById 和 trending 方法如下:
public function getById(int $id, array $columns = ['*'])
{
$cacheKey = 'post_' . $id;
if (Redis::exists($cacheKey)) {
return unserialize(Redis::get($cacheKey));
}
$post = $this->post->select($columns)->find($id);
if (!$post) {
return null;
}
Redis::setex($cacheKey, 1 * 60 * 60, serialize($post)); // 缓存 1 小时
return $post;
}
...
// 热门文章排行榜
public function trending($num = 10)
{
$cacheKey = $this->trendingPostsKey . '_' . $num;
if (Redis::exists($cacheKey)) {
return unserialize(Redis::get($cacheKey));
}
$postIds = Redis::zrevrange($this->trendingPostsKey, 0, $num - 1);
if (!$postIds) {
return null;
}
$idsStr = implode(',', $postIds);
$posts = $this->getByManyId($postIds, ['*'], function ($query) use ($idsStr) {
return $query->orderByRaw('field(`id`, ' . $idsStr . ')');
});
Redis::setex($cacheKey, 10 * 60, serialize($posts)); // 缓存 10 分钟
return $posts;
}
对比缓存读取流程来理解上面引入缓存后的方法实现代码对你来说应该不会有什么问题。
测试引入缓存后的代码
接下来,我们来测试下引入缓存后的代码是否可以正常工作,为了验证确实命中了缓存,我们可以安装 Laravel Debugbar 扩展包进行对比查看:
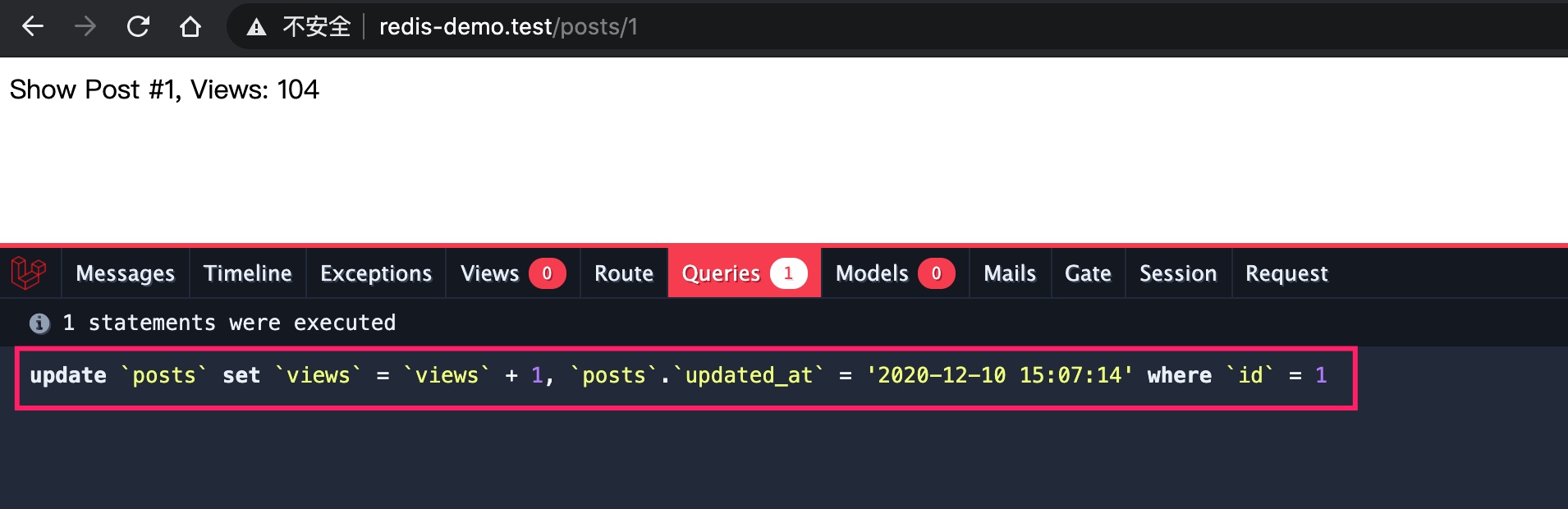
可以看到在数据库查询记录里面,不存在查询文章记录的操作,相应的模型实例数也是零,表明确实命中了缓存。
我们再来看热门文章排行榜:
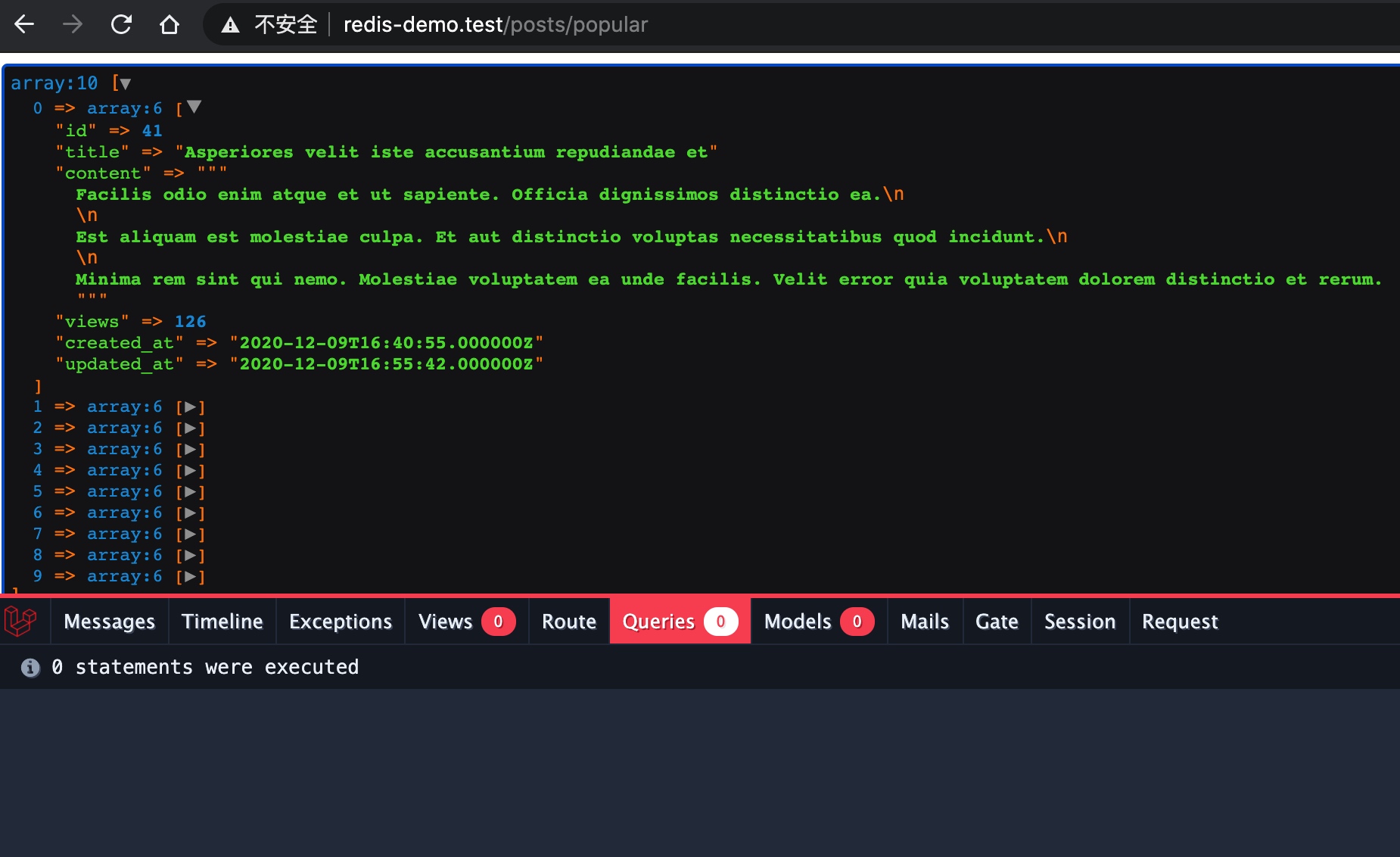
查询记录为空,模型实例数量也为空,说明成功命中了缓存。
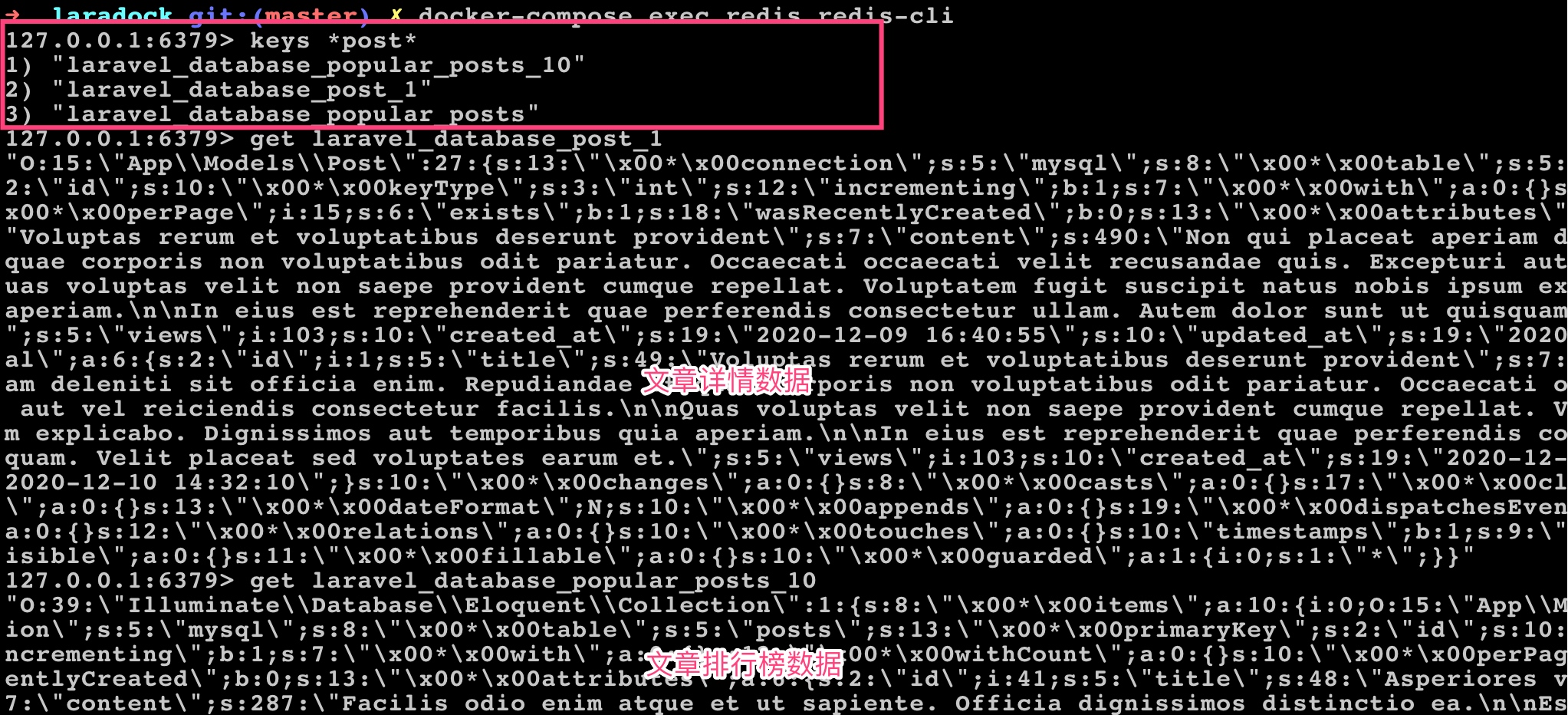
你可以到 Redis 命令行客户端去查看对应的缓存数据:
使用 Laravel 自带的缓存组件
当然,在 Laravel 项目中,如果使用 Redis 作为缓存存储器的话,推荐使用自带的缓存组件,在配置好 Redis 连接信息的基础上,只需要将 .env 中环境配置项 CACHE_DRIVER 的值设置为 redis 即可使用 Redis 实现缓存功能:
CACHE_DRIVER=redis
其底层的实现原理是在 CacheServiceProvider 中,会通过 CacheManager 来管理所有缓存存储器:
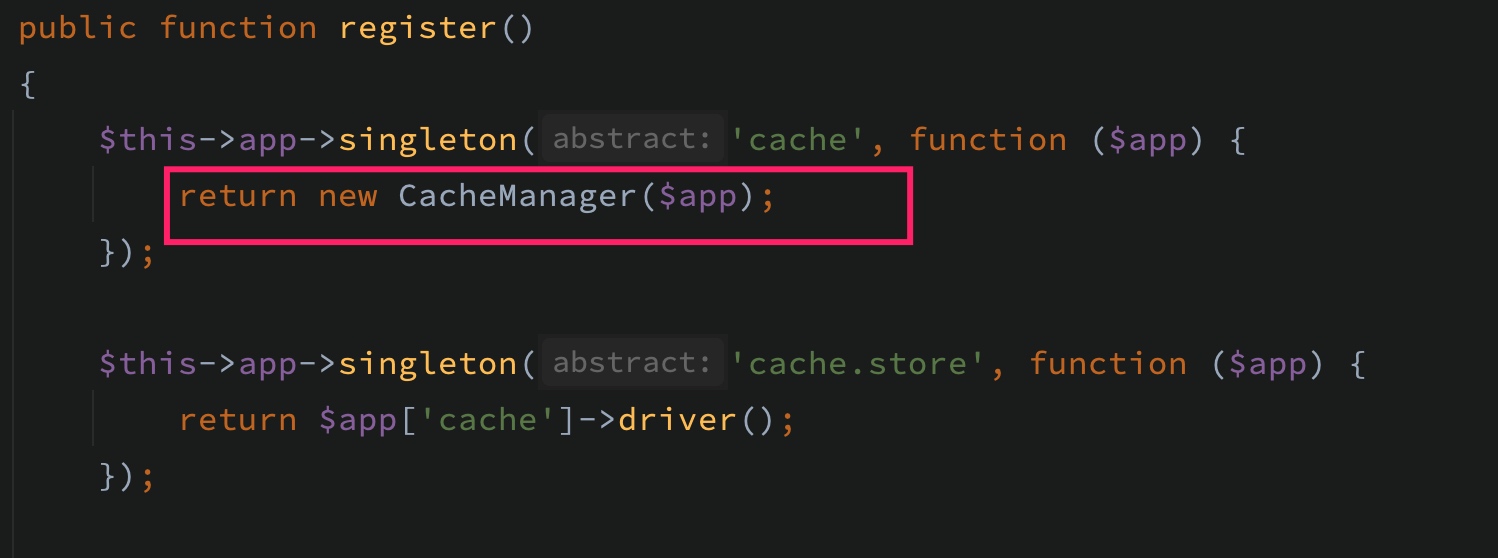
Cache 门面代理的就是这个对象实例,当我们在项目代码中基于 Cache 门面存取缓存项时,实际上调用的是 CacheManager 的魔术方法 __call:

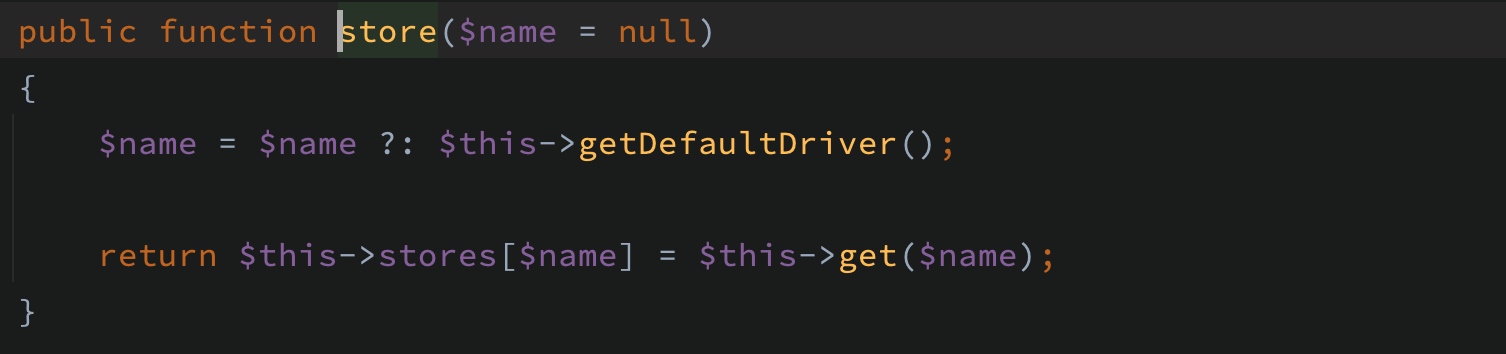
所有 Cache 门面上调用的缓存项操作方法最终会被 store 方法返回的默认缓存存储器进行处理:
这里我们将缓存驱动配置为 redis,就会调用 createRedisDriver 方法基于 RedisStore 创建缓存存储器:
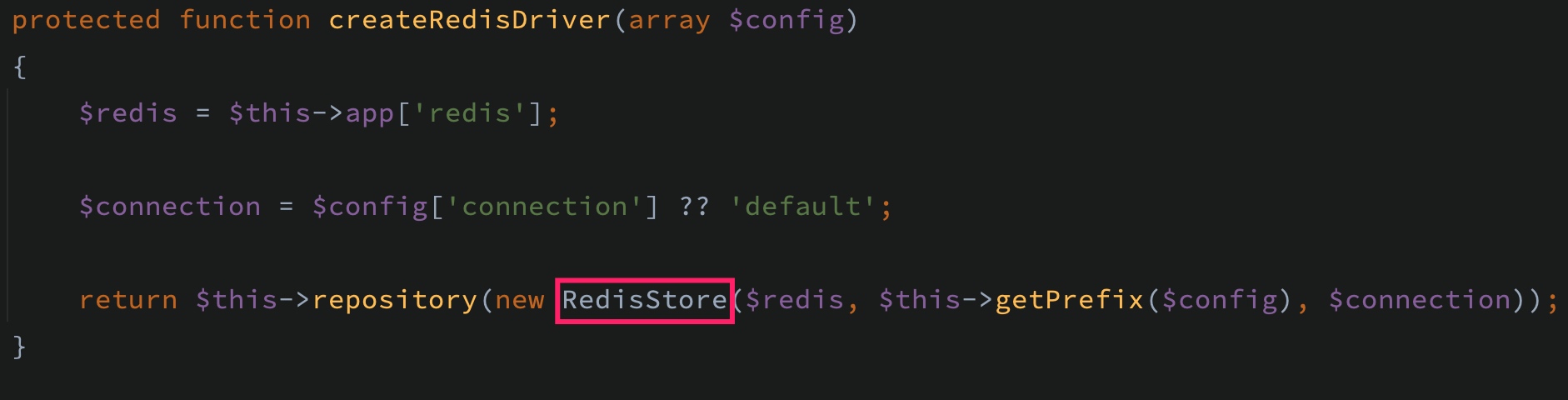
虽然外层被套上了 Repository 对象,但是这只是一个壳而已,是为了封装出统一的缓存操作 API,真正的存取逻辑还是在底层的缓存存储器中完成的,比如 redis 对应的存储器是 RedisStore,memcached 对应的存储器是 MemcachedStore,等等。
我们打开 RedisStore(vendor/laravel/framework/src/Illuminate/Cache/RedisStore.php),可以看到对应的缓存读取和设置方法源码:
/**
* 通过键名获取缓存项
*
* @param string|array $key
* @return mixed
*/
public function get($key)
{
$value = $this->connection()->get($this->prefix.$key);
return ! is_null($value) ? $this->unserialize($value) : null;
}
...
/**
* 设置带有过期时间的缓存项
*
* @param string $key
* @param mixed $value
* @param int $seconds
* @return bool
*/
public function put($key, $value, $seconds)
{
return (bool) $this->connection()->setex(
$this->prefix.$key, (int) max(1, $seconds), $this->serialize($value)
);
}
和前面我们基于原生 Redis 实现的代码类似,这里调用的是 Redis 连接实例上的 get 和 setex 方法获取和设置缓存,如果是缓存项是对象的话,还会进行序列化和反序列化操作。
不过这里没有提供 exists 方法的实现,在上一层的 Repository 类中定义了一个与之等价的 has 方法实现同样的功能:
public function has($key)
{
return ! is_null($this->get($key));
}
它是基于 get 方法实现的,此外,在 Repository 类中还提供很多其他实用的方法,比如 remember:
public function remember($key, $ttl, Closure $callback)
{
$value = $this->get($key);
// If the item exists in the cache we will just return this immediately and if
// not we will execute the given Closure and cache the result of that for a
// given number of seconds so it's available for all subsequent requests.
if (! is_null($value)) {
return $value;
}
$this->put($key, $value = $callback(), $ttl);
return $value;
}
该方法将缓存项的读取和设置合并为一个方法,调用该方法时,如果缓存项存在,则基于底层缓存存储器的 get 方法返回对应值,否则的话,通过回调函数参数和过期时间设置缓存项并将其返回。
我们使用这个方法重构前面的 PostRepo 缓存实现代码,最终结果是这个样子:
use Illuminate\Support\Facades\Cache;
public function getById(int $id, array $columns = ['*'])
{
$cacheKey = 'post_' . $id;
return Cache::remember($cacheKey, 1 * 60 * 60, function () use ($id, $columns) {
return $this->post->select($columns)->find($id);
});
}
// 热门文章排行榜
public function trending($num = 10)
{
$cacheKey = $this->trendingPostsKey . '_' . $num;
return Cache::remember($cacheKey, 10 * 60, function () use ($num) {
$postIds = Redis::zrevrange($this->trendingPostsKey, 0, $num - 1);
if ($postIds) {
$idsStr = implode(',', $postIds);
return $this->getByManyId($postIds, ['*'], function ($query) use ($idsStr) {
return $query->orderByRaw('field(`id`, ' . $idsStr . ')');
});
}
});
}
整体代码会简洁很多,在浏览器中访问文章详情页路由,首次访问的时候由于缓存项不存在,所以需要先做数据库查询:
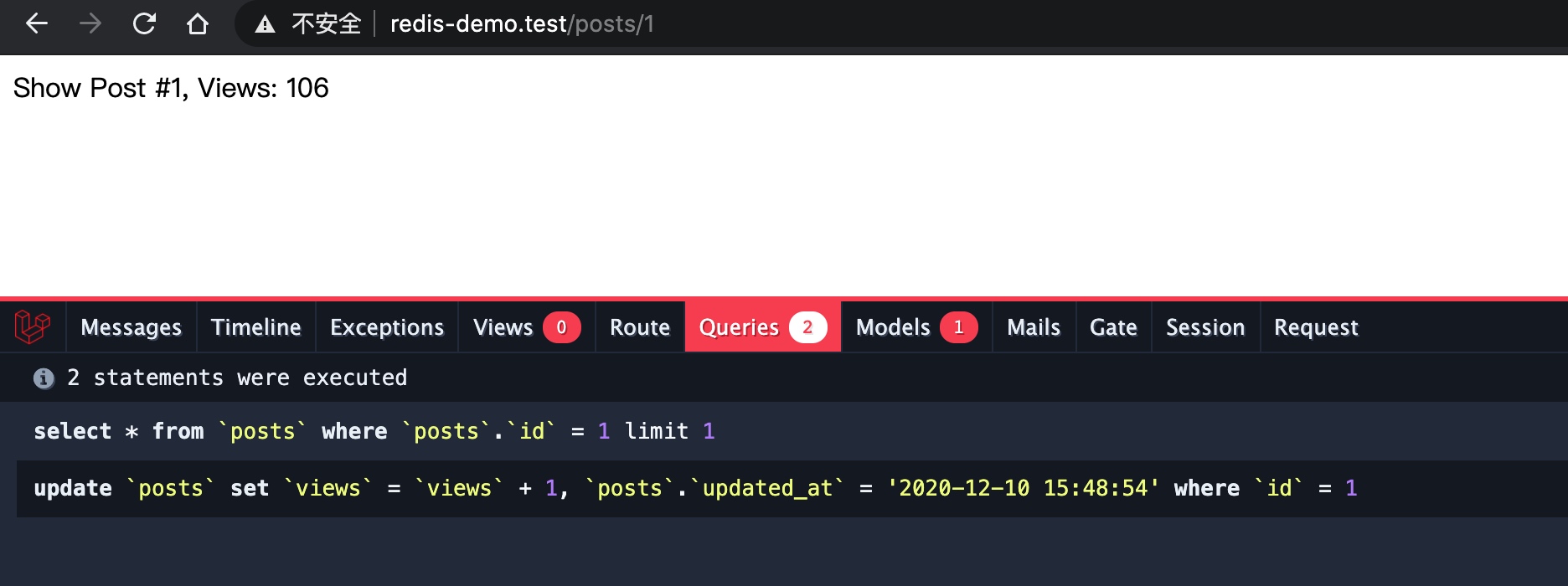
刷新该页面,由于命中了缓存,就不会再做数据库查询,而是直接返回对应的缓存项了:
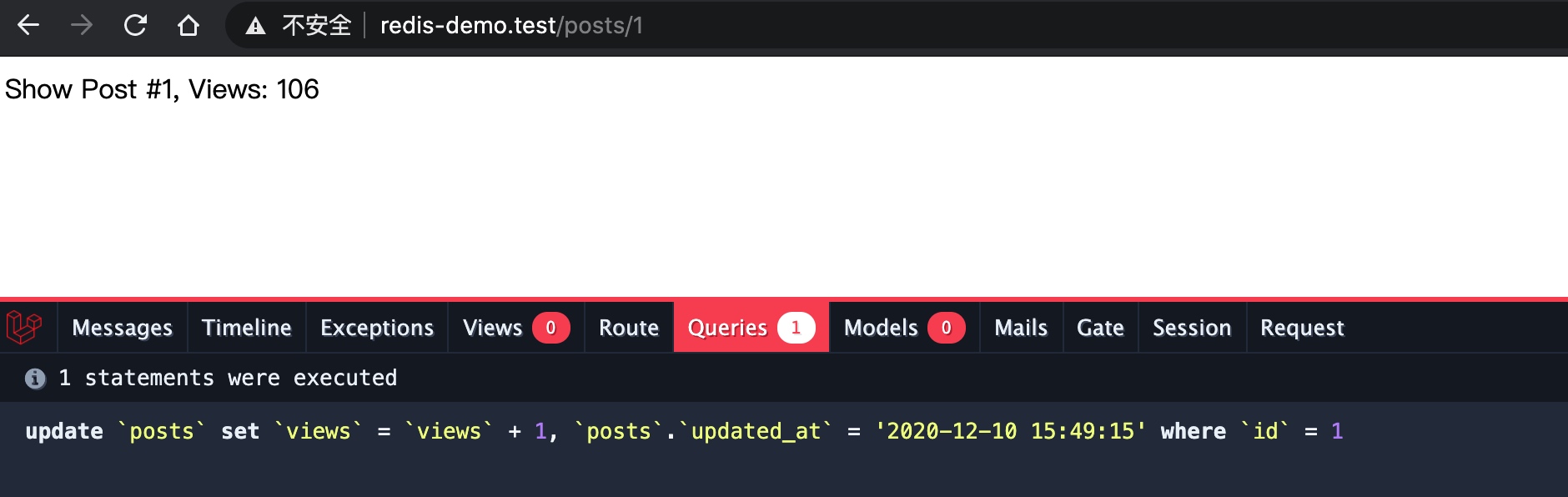
热门文章排行榜路由也是类似,这里不再重复演示了。
你可能已经注意到,Laravel 缓存组件有独立的缓存键前缀,这个前缀可以在 config/cache.php 中配置:
'prefix' => env('CACHE_PREFIX', Str::slug(env('APP_NAME', 'laravel'), '_').'_cache'),
默认值是 laravel_cache,所以即便 Cache 门面和 Redis 门面设置的缓存键同名,由于前缀不同,所以对应着不同的字符串键值对。
更多 Laravel 自带缓存组件的功能特性,请参考官方文档,这里就不一一介绍了。
13 Comments
在 PostController 控制器中通过 PostRepo 重构对文章模型实例的操作这段代码里面的popular()方法有错误;应该把
if($postIds)改成if(!$postIds)是的 感谢反馈 已修正
PHP 7.4 以后就支持这样的语法了 我不可能把编译不通过的代码贴出来
不知道$this->trendingPostsKey 是哪里定义的
看源码: https://github.com/nonfu/redis-demo/blob/main/app/Repos/PostRepo.php
Illuminate\Contracts\Container\BindingResolutionException Target class [App\Repos\PostRepo] does not exist. 报错
你没有引入这个类吧
大佬,我安装你写的PostRepo不行,但是把这个改成Postrepo就可以了,之前我用了 composer dump-autoload Generating optimized autoload files Class App\Repos\PostRepo located in D:/laragon/www/laravel/app\Repos\PostRepo .php does not comply with psr-4 autoloading standard. Skipping.
在使用Cache,里面保存的模型是没有使用序列化和反序列化。我想请问一下在将对象保存到缓存的时候,序列化和不序列化保存有什么区别吗