基于 Redis HyperLogLog 实现用户 UV 统计中间件功能
引子
在通过 Redis 实现全站访问计数器中,学院君已经给大家演示了统计用户 PV 的实现思路,今天我们来看看如何实现用户 UV 的统计。
统计用户 UV 和统计用户 PV 不同,不能只对统计指标对应的键值做简单的自增操作,还要对来自同一用户的浏览做去重操作,比如张三今天浏览了学院君网站首页 10 次,那么对应的 PV 需要累加 10,而 UV 只能算 1 个。
通过 SET 结构实现 UV 统计
基于去重功能,很多同学可能会联想到可以通过 Redis 的 SET 结构实现用户 UV 统计 —— 将统计指标+时间后缀作为键名,然后每当有用户访问时,将对应的用户标识通过 SADD 指令存储到这个 SET 结构即可,由于 SET 结构会自动帮我们去重,所以通过 SCARD 指令就能获取到用户 UV 了:
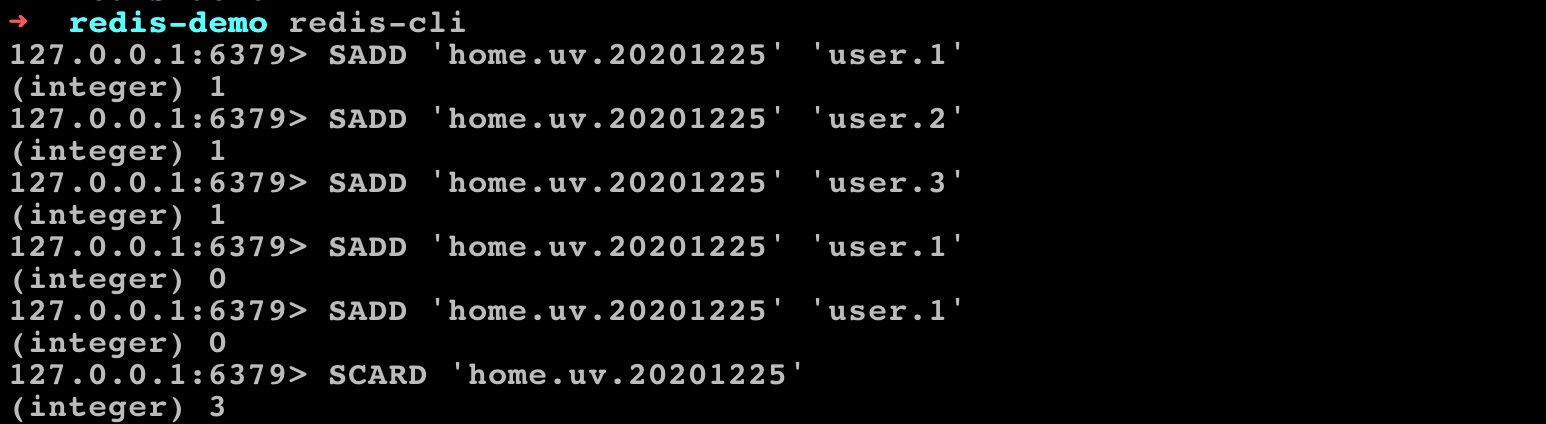
这么实现功能上是 OK 的,对于小型站点也没什么问题,但是如果放到大型站点就不合适了,比如我们要统计上百万不同页面的用户 UV,用户量级在千万级甚至亿级,为了维护每个页面用户 UV 统计的 SET 结构,需要耗费大量的 Redis 存储空间,对于爆款页面,所要维护的 SET 结构更是巨大,只是为了实现一个去重功能而已,有必要花费这么大的代价吗?有没有更好的解决方案呢?
SET vs HyperLogLog
对于这种访问量特别大的 UV 统计,其实是可以接收一定误差的,比如一百万的访问量,误差在几百上下完全没问题,因此我们可以使用 Redis 提供的高级数据结构 HyperLogLog 来实现这样的 UV 统计功能。
HyperLogLog 这个数据结构会占用固定的存储空间(12KB),同时存在一定误差(不超过 0.81%),因此对于统计标的在几百几千访问量的小型应用不太适合,这种情况下,使用 SET 数据结构实现就可以了,因为也不会占用多少存储空间,而且较小的访问量对精确性要求更高,SET 肯定是不存在误差的,但是对于统计标的在百万千万级的大型应用,使用 HyperLogLog 的优势就显现出来了,与 SET 相比占用的存储空间就不值一提了,而且误差相较于最终的统计体量而言也几乎可以忽略。
HyperLogLog 的基本使用
HyperLogLog 指令
HyperLogLog 只提供了三个指令:
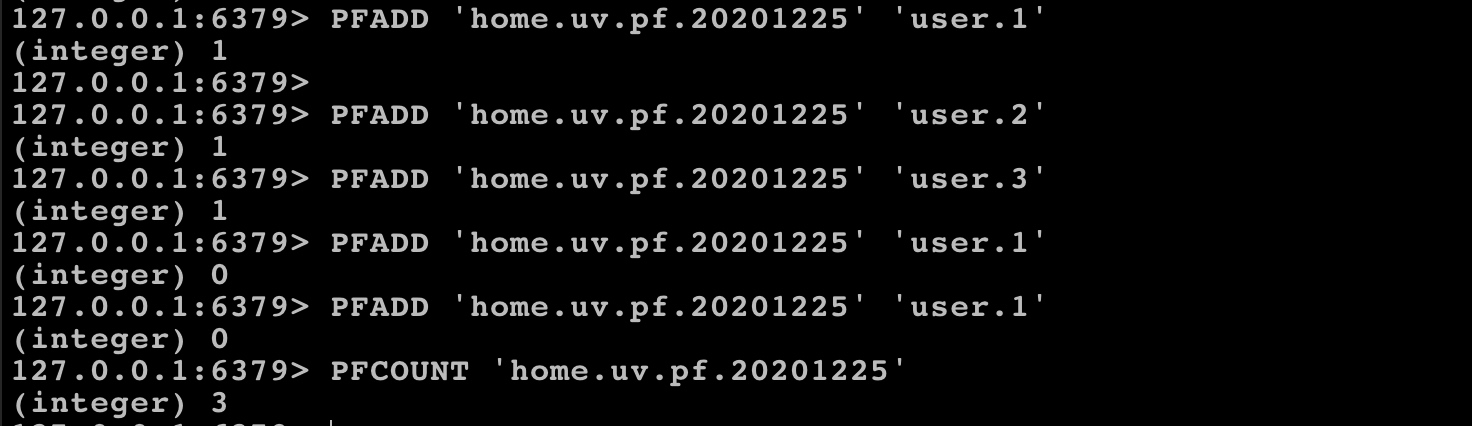
PFADD 用于往 HyperLogLog 中添加元素,PFCOUNT 用于统计 HyperLogLog 中的元素数量,PFMERGE 用于合并不同 HyperLogLog 的统计结果。和 SET 一样,HyperLogLog 也是会去重的:
模拟 UV 统计功能实现
对于数据量很小的统计,不存在误差,如果试图统计更多数据,比如万级,就会存在误差了,下面我们通过一个 Artisan 命令来模拟:
sail artisan make:command HyperLogLogDemo
然后编写这个命令类代码如下:
<?php
namespace App\Console\Commands;
use Illuminate\Console\Command;
use Illuminate\Support\Facades\Redis;
class HyperLogLogDemo extends Command
{
/**
* The name and signature of the console command.
*
* @var string
*/
protected $signature = 'uv:demo';
/**
* The console command description.
*
* @var string
*/
protected $description = 'UV Statistic Demo With Redis HyperLogLog';
/**
* Create a new command instance.
*
* @return void
*/
public function __construct()
{
parent::__construct();
}
/**
* Execute the console command.
*
* @return int
*/
public function handle()
{
$key = 'site.uv.pf.20201225';
Redis::pipeline(function ($pipe) use ($key) {
for ($i = 0; $i < 10000; $i++) {
$pipe->pfAdd($key, ['user.' . $i]);
}
});
$headers = ['Real UV', 'Statistic UV'];
$this->table($headers, [[10000, Redis::pfCount($key)]]);
}
}
这里为了加速 Redis 指令执行,我们使用了管道命令,当然,你可以可以通过数组一次性将所有统计数据添加到 HyperLogLog:
$users = [];
for ($i = 0; $i < 10000; $i++) {
$users[] = 'user.' . $i;
}
Redis::pfAdd($key, $users);
不过前一种更符合实际的场景。运行 uv:demo 命令,结果如下:

这里我们使用了 Artisan 命令的表格输出格式让结果显示更直观一些。
可以看到,实际 UV 是 10000,通过 HyperLogLog 统计 UV 是 9973,误差率是 0.27%。
如果你再次运行这个命令,结果还是一样,说明 HyperLogLog 具备去重功能,完全可以胜任大访问量的用户 UV 统计工作。
实现全站 UV 统计中间件
接下来,和 Laravel 全站 PV 统计功能一样,我们基于 HyperLogLog 来实现一个全站 UV 统计中间件。
通过如下 Artisan 命令创建一个全局中间件:
sail artisan make:middleware SiteUV
然后编写生成的中间件类实现代码如下:
<?php
namespace App\Http\Middleware;
use Closure;
use Illuminate\Http\Request;
use Illuminate\Support\Facades\Auth;
use Illuminate\Support\Facades\Redis;
class SiteUV
{
/**
* Handle an incoming request.
*
* @param \Illuminate\Http\Request $request
* @param \Closure $next
* @return mixed
*/
public function handle(Request $request, Closure $next)
{
// 按天为维度统计站点 UV
$key = config('app.name') . '.uv.' . date('Ymd');
// 根据用户是否登录获取用户唯一标识
if (Auth::check()) {
$userIdentifier = Auth::user()->getAuthIdentifier();
} else {
$userIdentifier = $request->getClientIp();
}
Redis::pfAdd($key, [$userIdentifier]);
return $next($request);
}
}
在 App\Http\Kernel 的 $middleware 属性数组中添加这个中间件,将其作为全局中间件应用到所有的路由访问:
protected $middleware = [
...
\App\Http\Middleware\SiteVisits::class,
\App\Http\Middleware\SiteUV::class,
];
访问 http://redis.test 的任意路由,可以看到对于同一个用户/客户端,PV 和 UV 的结果是不一样的:

注:由于我们前面在广播教程中取消了 Redis 键名前缀
laravel_database_,所以这里都不需要添加这个前缀就可以访问对应的键值了。
PV 会不断累加,而 UV 始终是 1。
6 Comments
我按照这个教程,添加的了UV统计功能,可是,结果显示比百度统计相差很多,总是多出来很多UV。总是这样。不知道哪里问题。我有些怀疑百度统计代码错误,可是,自己没保证。请问大家遇到这种情况了吗?该怎么处理呢?
站长一直没有动静,网友也不见了。现在网站经营遇到什么问题了?无人处理问题了吗?
这里的uv统计一直不准确,我再次pfadd 和pfcount在别处,也是无法得到准确数字。请站长帮助研究查明原因,多谢!!!
这种结构本来就有误差啊。量小的话用set
这里面没有排除爬虫 如果是公开网站 一半以上数据是爬虫过来爬的
我使用了composer 包Jenssegers\Agent\Agent过滤爬虫,但是,结果还是和百度统计相差很大,怀疑或者是百度统计代码错误,或者是这个包有错误,或者似乎自己代码有错误。但是,这个包反应是可以的。百度统计不敢怀疑,但是,自己代码依托教程,也是可以的,所以,依然非常困惑,这个问题迟迟不能得到解决,非常bug,高度怀疑,可能百度统计过滤了其他的agent,不只是爬虫,可能其他agent也过滤了。但是,具体技术细节,难以知道了。这个bug,只能保存了。。盼望站长可以研究下解决方法,尽管,很难了。。。