基于任务链和批处理生成复杂报告
数据的尺寸和结构决定了生成报告的复杂性和耗时,将其放到后台执行可以让响应更快,同时更高效地使用系统资源。
对于一个很大的电子表格,需要读取数据,然后将其转化一个更简单的格式,用于查询、排序、生成最终的报告。我们可以对这个任务进行分解:
- ExtractData(解析)
- TransformChunk (转化)
- StoreData(存储)
- GenerateSummary(生成报告)
然后通过消息队列以任务链的方式进行异步批处理。
接下来,我们来演示具体实现这个任务链的实现和执行。
任务链和批处理
我们可以把从电子表格读取的数据拆分成多个子块,以便通过多个队列任务并发处理数据,让报告生成速度更快:
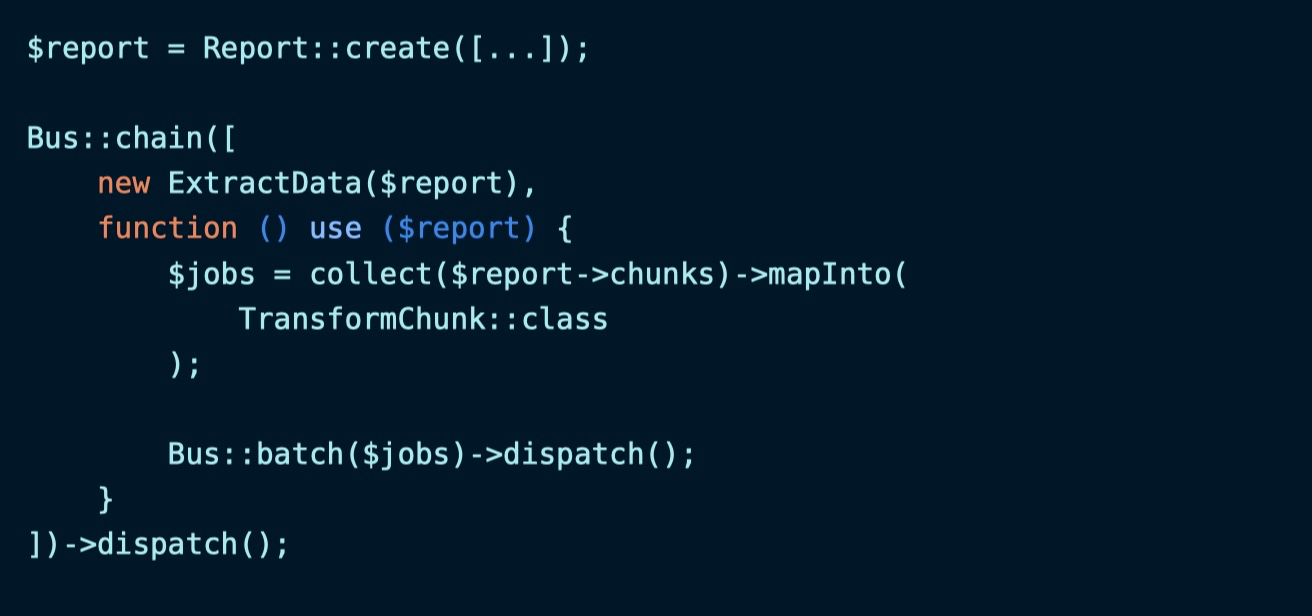
这是一个任务链,基于 ExtractData 读取完电子表格数据后,下一步将对应区块的数据通过 TransformChunk 进行转化,最后再通过批处理任务对转化结果进行处理。
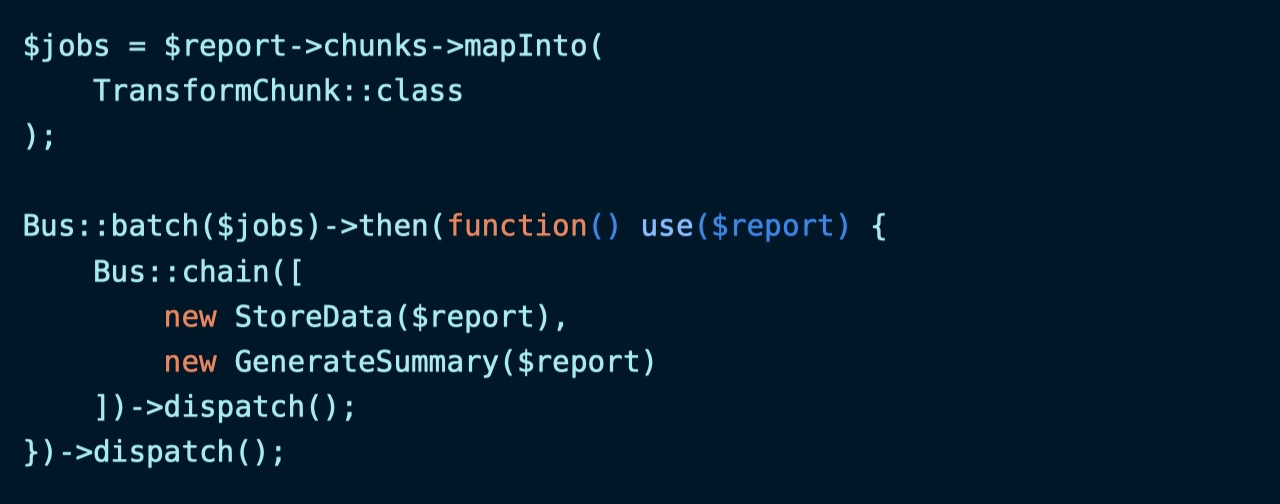
批处理完成后分发任务链
批处理运行完成后,将对应处理结果推送到 StoreData 和 GenerateSummary 任务链依次进行处理,最终生成报告:
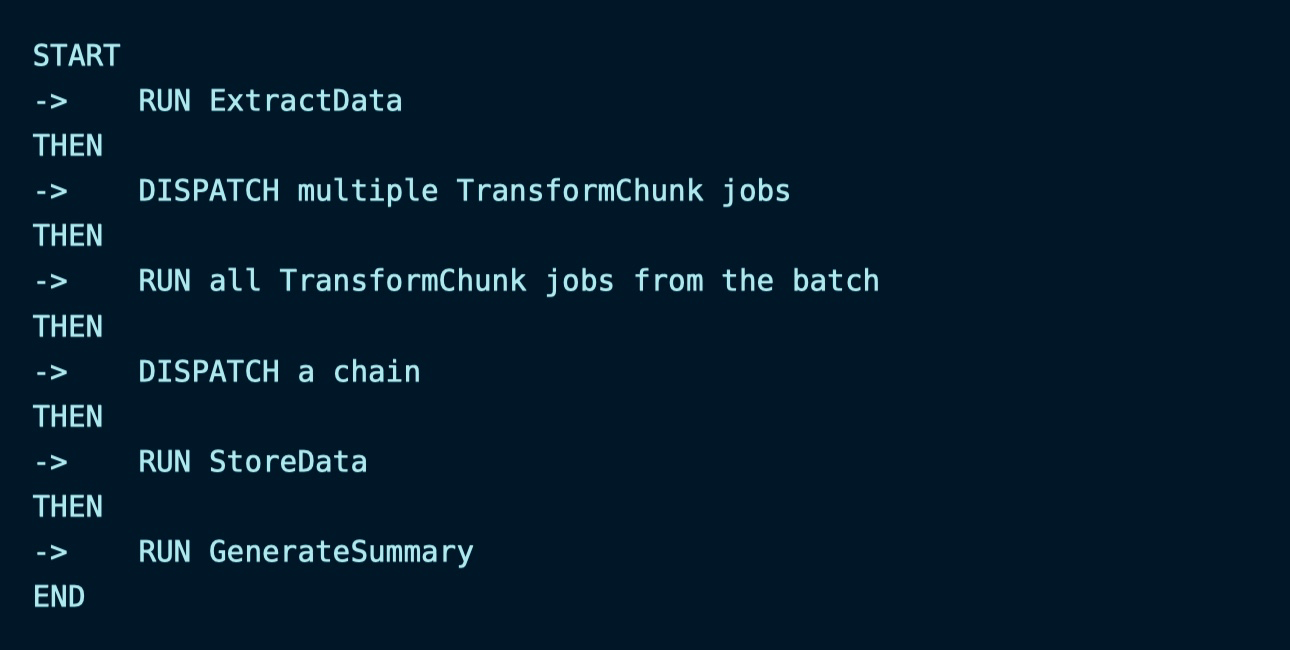
整体处理流程如下:
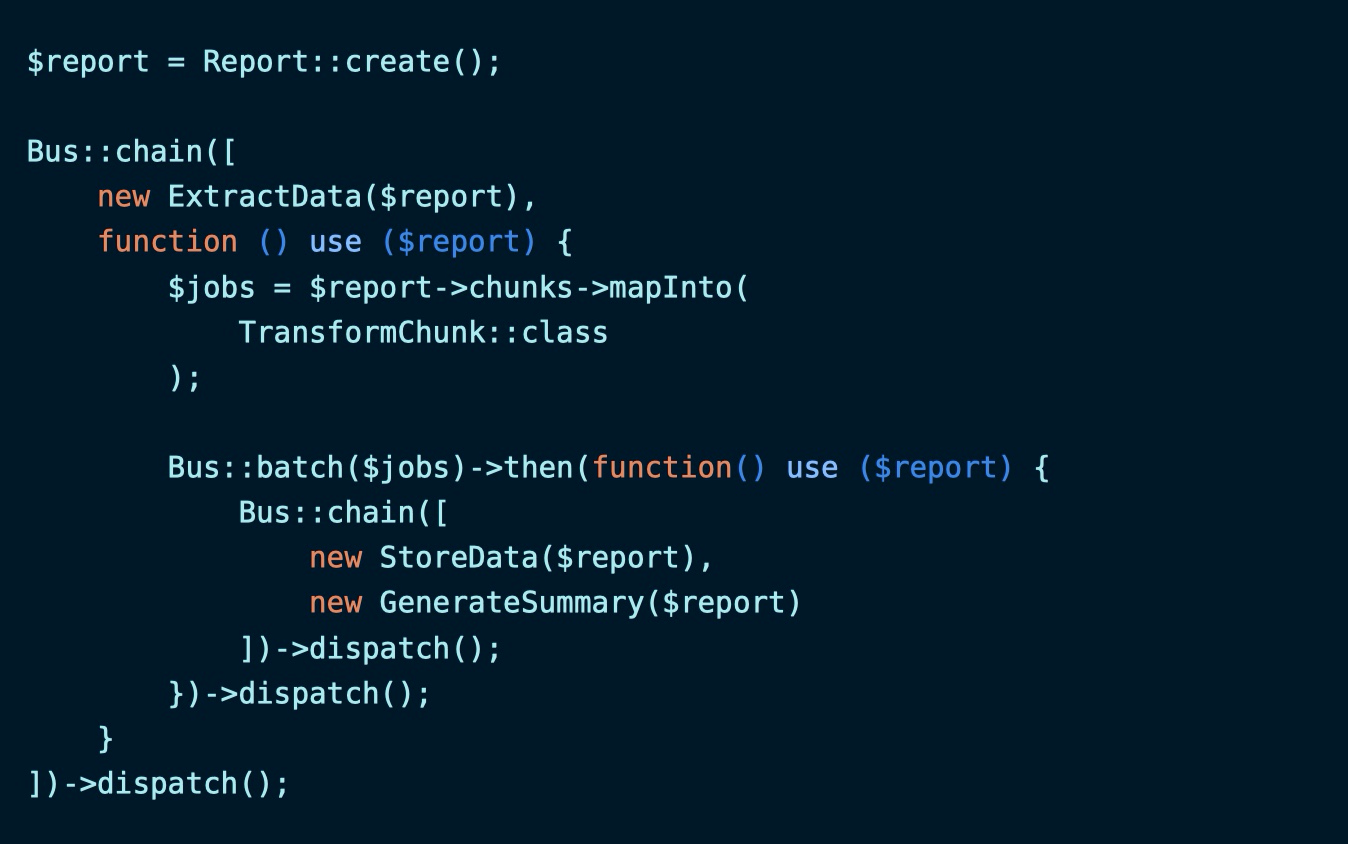
完整代码如下:
让可读性更好
上面的代码让人看起来很困惑,并且随着功能复杂度提高,可读性更差。
为了让其可读性更好,我们创建一个 ReportGenerationPlan 类:
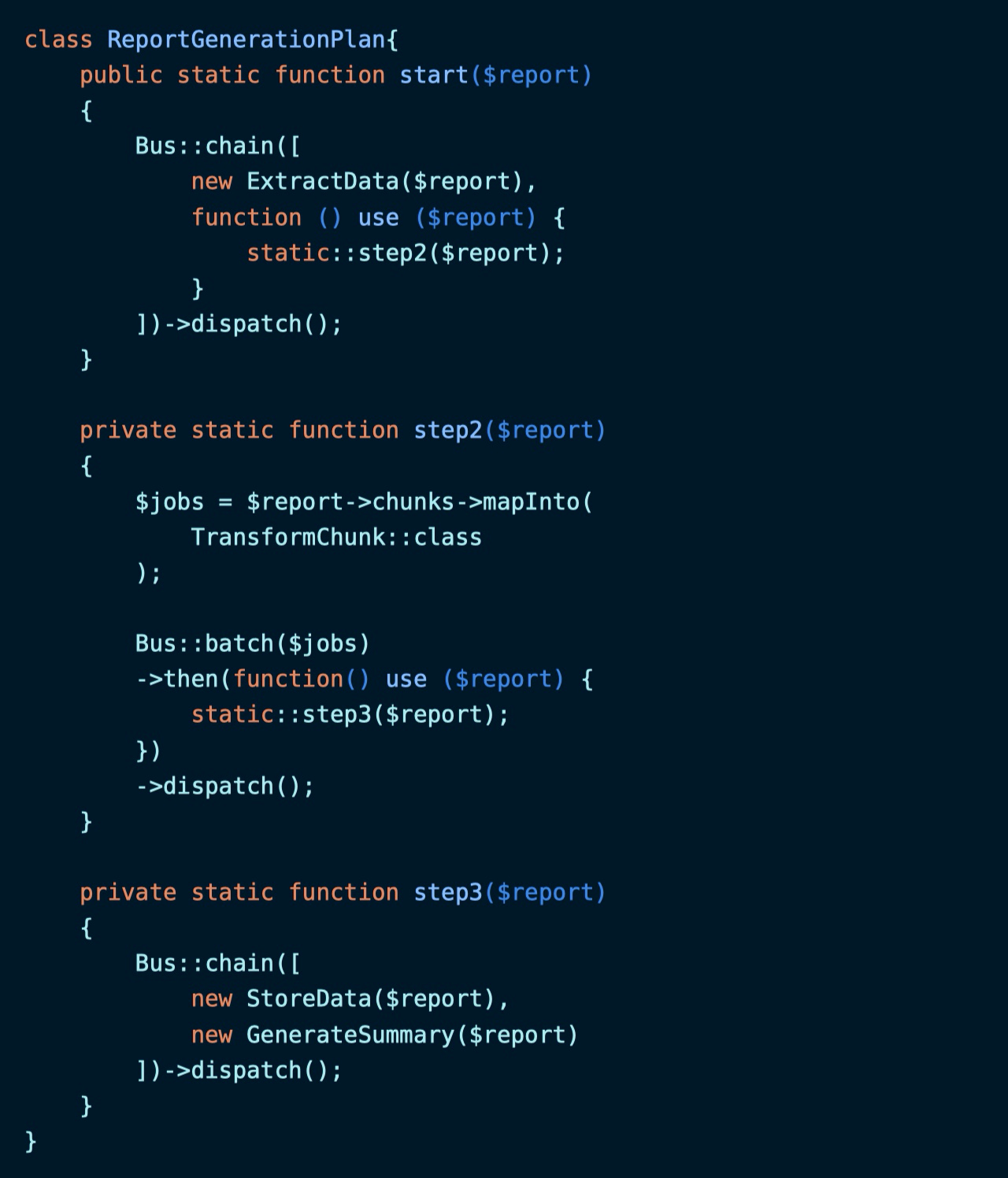
这里之所以使用
static而不是$this是因为序列化操作时包含$this的闭包会报错。
然后我们可以调用 start 方法来启动任务:

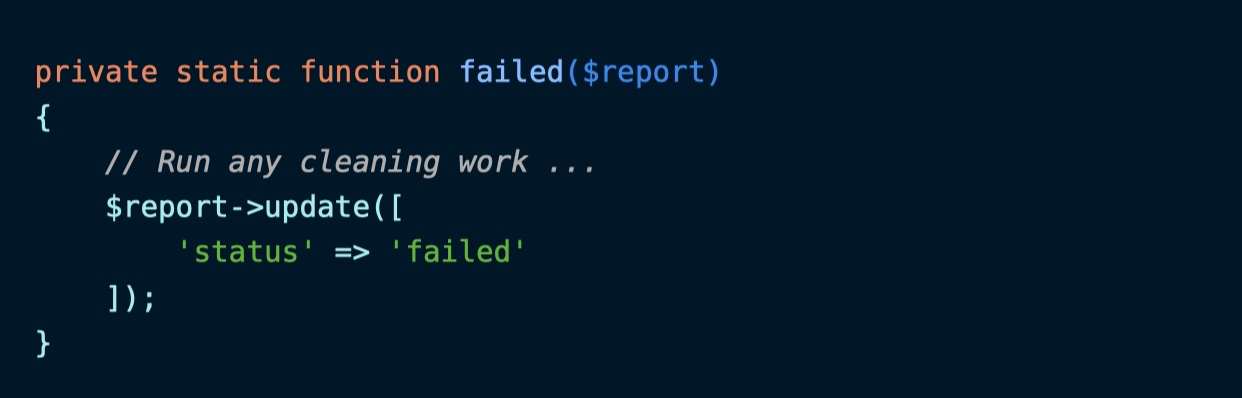
处理队列任务失败
如果任务执行出错,则需要清理所有不必要的文件和临时数据,这可以通过在 ReportGenerationPlan 中新增 failed 方法来实现:
然后在任务链和批处理中通过 catch 方法调用失败处理操作:
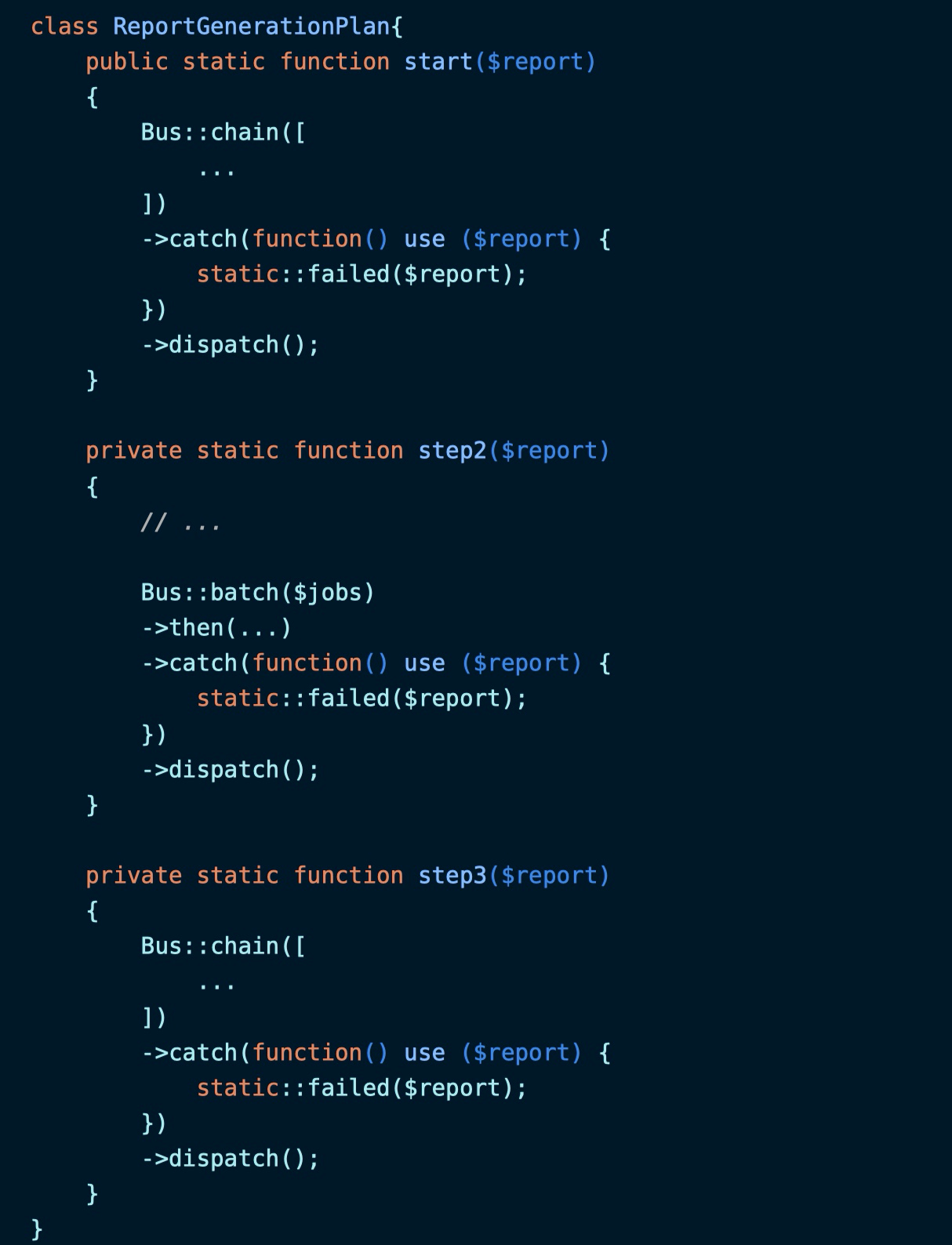
无评论